

Statistika o důchodech na náš warehouse
Vytvoření datového skladu v projektu Statistika důchodů ČSSZ
Pojem DataWarehouse se stal součástí slovníku každého pracovníka v oblasti informačních technologií. Rozšiřte svůj slovník o pojem KMX Warehouse© verze 2.0.
V roce 1996 se Česká správa sociálního zabezpečení (ČSSZ) rozhodla inovovat dosavadní statistický systém v oblasti důchodových dávek. Úvodní studie formulovala následující cíle:
- sjednotit uložení dat o důchodech ve statistické databázi, která bude sloužit jako základní zdroj dat pro jejich zobrazení a další zpracování různými sw-nástroji,
- zajistit dynamický přístup k datům nejen pro standardní statistické výstupy (ročenka), ale i pro uživatelsky definované výstupy z průběžně vznikajících statistických šetření,
- poskytnout koncovým uživatelům interaktivní dotazovací systém nad datovým skladem,
- propojit statistickou databázi s nástrojem (statistickou nadstavbou) umožňujícím využití statistických metod, zejména pro analýzu časových řad a modelování relací mezi proměnnými.
V rámci projektu byla realizací pověřena společnost Komix, která má s tvorbou datových skladů značné zkušenosti. Společnost již několik let vyvíjí vlastní systém KMX Warehouse©. Od roku 1993 je tento systém provozován na Generálním ředitelstvím cel. KMX Warehouse© umožňuje vytvoření a správu datového skladu, který poskytuje uživatelům služby pro realizaci analytického zpracování dat (tzv. OLAP). Vzhledem k tomu, že systém je otevřený, lze jej upravit potřebám konkrétního zákazníka.
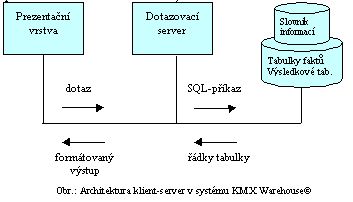
 Projekt Statistika důchodů ČSSZ je realizován v systému KMX Warehouse© verze 2.0. V této verzi systému je použita tříúrovňová architektura, separující vlastní datový sklad, logickou a prezentační vrstvu aplikace. Datový sklad je vybudován v databázi Informix, logika aplikace je skryta v aplikačním serveru naprogramovaném v jazyce C na UNIXu. Pro zadávání dotazů je vytvořena klientská aplikace programovaná v jazyce C++ pro prostředí MS Win 32 (Windows 95 nebo Windows NT). Pro prezentaci výsledků je použit tabulkový kalkulátor MS Excel.
Projekt Statistika důchodů ČSSZ je realizován v systému KMX Warehouse© verze 2.0. V této verzi systému je použita tříúrovňová architektura, separující vlastní datový sklad, logickou a prezentační vrstvu aplikace. Datový sklad je vybudován v databázi Informix, logika aplikace je skryta v aplikačním serveru naprogramovaném v jazyce C na UNIXu. Pro zadávání dotazů je vytvořena klientská aplikace programovaná v jazyce C++ pro prostředí MS Win 32 (Windows 95 nebo Windows NT). Pro prezentaci výsledků je použit tabulkový kalkulátor MS Excel.
Datový sklad je spravován databázovým serverem Informix OnLine DS 7.24 v prostředí operačního systému HP-UX na počítači HP 9000. Databáze obsahuje primární data (data o důchodech, včetně jejich kompletní historie), slovník informací (metadata datového skladu), tabulky dimenzí a faktů a výsledkové tabulky.
Systém je rozčleněn na subsystémy pro import dat, agregaci dat, dotazovací server a prezentační vrstvu.
Subsystém pro import dat zajišťuje vstup dat do systému. Zdrojem informací pro datový sklad jsou "styčné soubory" vytvářené z dat provozního systému ČSSZ. Subsystém však zajišťuje vstup dat také z jiných zdrojů (demografické a makroekonomické údaje, apod.).
V průběhu importu styčných souborů je provedena aktualizace primárních dat datového skladu. Při aktualizaci dochází k transformaci dat do relační podoby a jejich typové a logické kontrole. Do databáze byly přeneseny statistické ukazatele 2,5 mil. důchodců a 3 mil. vyplácených důchodů. Díky "ortodoxně relačnímu" uložení primárních dat nepřesáhla velikost databáze 4 GB.
Podpora importu heterogenních dat z různých zdrojů rozšiřuje možnost použití subsystému.
Subsystém pro agregaci dat zajišťuje předzpracování dat do podoby, která umožňuje efektivní analýzu statistických dat "na počkání". Agregovaná data ve formě "multidimenzionálních kostek" jsou ukládána do tabulek v relačním databázovém systému Informix. Data jsou uložena v nenormalizovaném tvaru s různým stupněm agregace. Uvedené uložení dat umožňuje získat v krátké době odpovědi na dotazy, které není možné předem připravit, ale které mohou podporovat různá průběžně vznikající statistická šetření.
Budování datového skladu je založeno na vytvoření definic dimenzí a tabulek faktů uložených ve slovníku informací. Administrace datového skladu představuje správu těchto definic. Administrátor může průběžně optimalizovat budování datového skladu; optimalizace spočívá v hledání vhodného poměru mezi rychlostí získávání požadovaných analýz a objemem a dobou vytváření agregovaných dat.
Budování dimenzí datového skladu má jeden specifický rys. Z jednoho prototypu dimenze lze v průběhu času vytvořit více otisků s různými množinami hodnot dimenze, přičemž platnost každého otisku je časově omezena. U každého požadavku na data v datovém skladu je uveden úhel pohledu (časový okamžik řezu dimenzí). Podle jeho hodnoty je při zpracování požadavku automaticky vybrán příslušný otisk. Uživateli, pokud používá různé úhly pohledu, se dimenze jeví dynamická.
Použití dynamických dimenzí výrazně rozšiřuje možnosti uživatelů systému. Výhoda se projeví především tehdy, pokud se v datovém skladu používají dimenze s často se měnícími hodnotami.
Dotazovací server zpracovává požadavky klientské aplikace. Podle typu požadavku server provede např. uložení specifikace dotazu do slovníku informací, spuštění dotazu nebo předání výsledků zpracovaného dotazu klientské aplikaci.
Při realizaci požadavku na spuštění dotazu provádí dotazovací server analýzu definice dotazu, na jejímž základě je proveden výběr zdrojových tabulek a sestaven SQL-příkaz pro databázový server. Výběr zdrojových tabulek faktů probíhá ve třech fázích: výběr vhodných statistických prostorů, výběr vyhovujících tabulek faktů ze skeletu statistického prostoru a zvolení optimální tabulky faktů.
Výběr vhodných statistických prostorů probíhá podle zvolených parametrů statistiky (druh statistiky, úhel pohledu, atd.). Při výběru vyhovujících tabulek se hledají tabulky ve skeletu prostoru, které obsahují všechny dimenze v požadovaných (nebo podrobnějších) stupních agregace. Poslední krok, optimalizace výběru zdrojové tabulky ze skeletu prostoru, je řešen pomocí optimalizačního algoritmu založeného na hledání minimální vzdálenosti ve speciální metrice statistických prostorů.
Použití dotazovacího serveru v architektuře klient-server vede k minimalizaci komunikace a k minimalizaci nároků na hardware a operační systém klientského počítače.
Subsystém pro prezentaci dat umožňuje uživateli vytvářet statistické přehledy, ať již standardní statistické výstupy (statistická ročenka), nebo výstupy z průběžně vznikajících statistických šetření ("ad hoc" dotazy). Uživatel požadavky specifikuje pomocí dotazů. Po dokončení specifikace (provedení výběru požadovaných dimenzí a faktů, zadání filtračních podmínek, podmínek pro řazení, atd.) je dotaz předán dotazovacímu serveru ke zpracování. Dotaz je možné spustit v režimu OFF LINE (dotaz je zařazen do fronty dotazů), nebo v režimu ON LINE (zpracování dotazu však nesmí překročit dobu 2 minut, po této době je dotaz automaticky převeden do režimu OFF LINE).
 Uživatelské rozhraní je
Uživatelské rozhraní je
navrženo tak, aby bylo pro koncového uživatele snadno ovladatelné a zakrývalo veškerou složitost dotazovacího serveru. Pro specifikaci dotazu není potřebná znalost SQL-příkazů! Převedení definice dotazu do SQL-příkazů je provedeno až na úrovni dotazovacího serveru.
Při prezentaci jsou výsledky zpracovaných dotazů formátovány a zobrazeny v tabulkovém kalkulátoru MS Excel v kontingenčním nebo relačním tvaru.
Použití kombinovaného zpracování dotazů (režimy ON LINE a OFF LINE) patří k pozitivním rysům systému. Uživatel nemusí mít strach, že v případě nevhodně položeného dotazu v ON LINE-režimu na dlouhé minuty zablokuje svůj počítač. Buď se dotaz vyhodnotí do 2 minut, nebo se zpracování dotazu automaticky přeruší a dotaz se zařadí do fronty dotazů - tím se aplikace uvolní pro další práci.
Vzhledem k pozitivním rysům KMX Warehouse© verze 2.0 jsme přesvědčeni, že se systém stane oblíbeným nejen v ČSSZ, ale i u dalších zákazníků.
| Slovníček pojmů |
|---|
|
Dimenze je pohled na data v datovém skladu podle určitého hlediska. Typickými dimenzemi jsou např. období vzniku, pohlaví, územní jednotky. Kombinací n pohledů na data vzniká "n-dimenzionální kostka" (odtud název dimenze). Dimenze je složena ze stupňů dimenze, mezi kterými je definována určitá hierarchie. Hierarchie dimenze může být jednoduchá (území - okres, kraj, republika), nebo stromová (invalidizace - diagnózy, skupiny diagnóz podle WHO, skupiny diagnóz podle Ministerstva práce a sociálních věcí).
Tabulka faktů je reprezentací "multidimenzionální kostky" v relačním databázovém systému. Jelikož tabulka faktů představuje spojení statistických faktů s dimenzemi, jsou řádky tabulky faktů tvořeny:
a) kombinací hodnot atributů odpovídajících dimenzí,
b) hodnotami faktů pro danou kombinaci hodnot atributů dimenzí.
Hierarchie dimenze ukazuje možnosti agregace faktů (tj. možnosti vytváření různě agregovaných tabulek faktů). Tabulka faktů, která byla vytvořena s použitím nejnižších stupňů dimenzí, se nazývá atomická tabulka faktů, ostatní tabulky nazýváme agregované tabulky faktů.
Statistický prostor: atomická tabulka faktů a všechny agregované tabulky faktů, které lze z atomické tabulky faktů odvodit, tvoří statistický prostor. Statistický prostor je určen druhem statistiky, úhlem pohledu a časovým obdobím. Pro každý druh statistiky (statistika nově vzniklých důchodů, statistika zaniklých důchodů atd.) je definován prototyp atomické tabulky faktů. Úhel pohledu určuje časový okamžik řezu dimenzemi. Časové období určuje časový rozsah dat ve statistickém prostoru. Seznam skutečně vytvářených tabulek faktů (obsahující atomickou tabulku faktů a vybrané agregované tabulky) tvoří skelet statistického prostoru.
|
Petr Stupka, stupka@komix.cz
| 










